

Technical analysis introduces data-mining bias because of the reuse of data. Due to this fact, trading signals based on small samples are not just naive, they are very dangerous. The problem of small samples can be resolved only if they are increased. Anything else is a cheap shot, it does not solve the problem and could also increase the bias.
Data-mining bias cannot be eliminated with more data-mining bias. This is what the trading literature tries in effect and these are often very cheap shots that try to conceal the problem behind obscure methods that luck a mathematical justification. Data-mining bias results in spurious correlations. This is due to the presence of a confounding factor. This factor is revealed when samples are increased. Therefore, the objective would be to increase the sample size. Any attempt to identify the confounding factor directly can only introduce more data-mining bias.
Those who use scanning programs or visual chart analysis to identify market entry signals based on indicators, chart patterns candlesticks and related techniques, must know their sample size and its relevant descriptive statistics. But the fact is that most do not even know the sample size or base decisions on very small samples. A pattern that has occurred X times in SPY since inception, with X < 30 for example, and made a profit 70% of the time is in most cases an artifact of data-mining bias and will in the longer-term generate as many losses as they are necessary so that the return before trading friction is included drops to zero. Only by increasing the sample size one can determine whether a specific pattern is not a fluke but represents market inefficiency. This can be done by portfolio backtesting on comparable securities. By comparable I mean that equity patterns are tested on equity data, forex patterns are tested on forex data, and so on. This is because the dynamics of different markets vary.
Example
This is an example of a scan of daily data of 12 popular ETFs from yesterday for profit target and stop-loss equal to 2% and also for an exit at the close of the entry bar. The entry is at the open. This is an example of quant trading using Price Action Lab, a data-mining application that produces the same output each time it encounters the same conditions because it is not based on random permutations. It also allows portfolio backtesting and other cross-validation tools for checking and analyzing the significance the results.
Workspace setup
Below is shown the scan workspace setup for 12 popular ETFs (DBC, DIA, EEM, GLD, IWM, QQQ, SLV, SPY, TLT, USO, XLE, XLF) with adjusted data since inception and two scan lines, one for 2% profit target and stop-loss and another for exit at the close of the entry bas (NC):
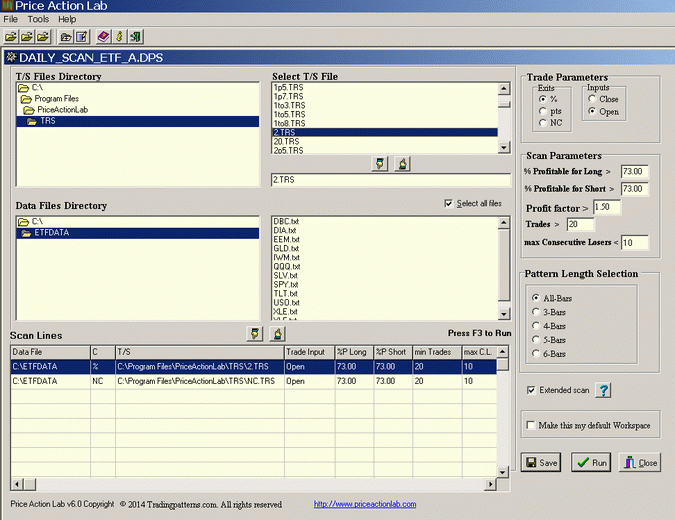
A small profit target and stop-loss of 2% is used in the first scan line to avoid curve-fitting to past data. Based on the above workspace, we are looking for patterns in all ETFs with more than 20 trades, a win rate of at least 73% and profit factor greater than 1.50.
Results
The following results were obtained:
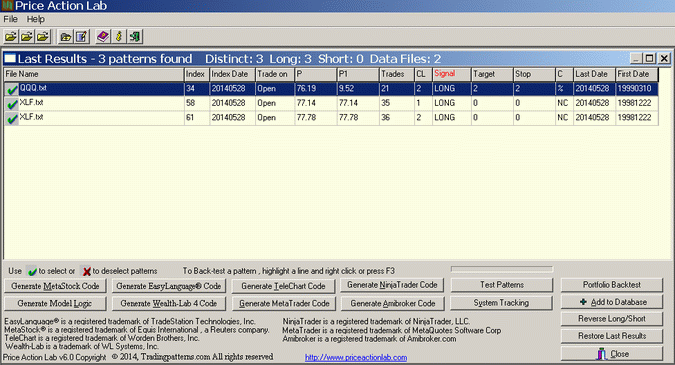 In the scan results above each line corresponds to an exact pattern. P is the pattern win rate, P1 is the 1-Bar win rate, Trades is the number of trades, CL is the maximum number of consecutive losers and Target and Stop the values of the profit target and stop-loss. C indicates the type of target and stop-loss.
In the scan results above each line corresponds to an exact pattern. P is the pattern win rate, P1 is the 1-Bar win rate, Trades is the number of trades, CL is the maximum number of consecutive losers and Target and Stop the values of the profit target and stop-loss. C indicates the type of target and stop-loss.
Three long patterns that fulfill the performance criteria set on the workspace as of the close of the last bar in the historical data files were identified: one in QQQ data and two in XLF data. For most technical traders this is where the analysis stops, whether that was done with the use of software, like in this case, or manually. But actually, this is where the serious analysis begins. The samples are small and we must determine whether the identified patterns are significant and not artifacts of data-mining bias and spurious correlations. Therefore, we will perform several portfolio backtests to try to determine that.
Portfolio backtest on all Dow-30 stocks
The first test involves a portfolio backtest on all Dow-30 stocks. These are only 30 stocks and it is done to expedite the analysis. If the test is positive, then we can move to more time-consuming ones. Below are the results of a portfolio backtest of the pattern on all Dow-30 stocks with adjusted data since 01/2000:
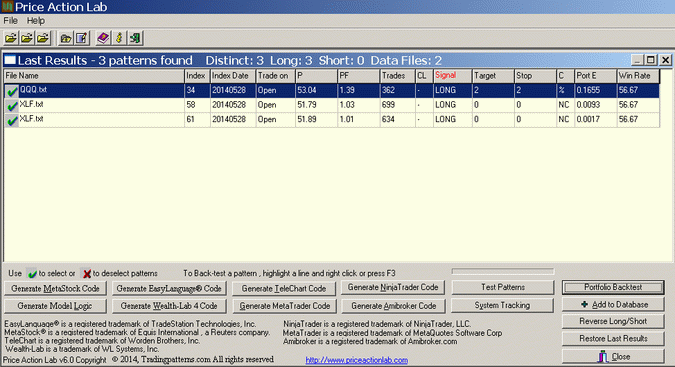
In the scan results above, each line corresponds to an exact pattern. P is the pattern win rate, Trades is the number of trades and Target and Stop the values of the profit target and stop-loss. C indicates the type of target and stop-loss (%, points, or next close exit). In the case of portfolio backtests, PF is the portfolio profit factor, PortE is the portfolio expectation and Win Rate is the proportion of securities with positive expectation.
With this test, the QQQ pattern trade sample was increased from 21 to 362 and the resulting portfolio profit factor is 1.36, a significant number. The portfolio win rate is 53.04% as the pattern was profitable in 56.67% (17) of the Dow-30 stocks. The performance of the XLF patterns shows high probability they are flukes because profit factors are very close to 1.
Portfolio backtest on all 24 popular ETFs
The next portfolio test is performed using data since inception of 24 popular ETF, other than those used in the scan for patterns. Below are the results:
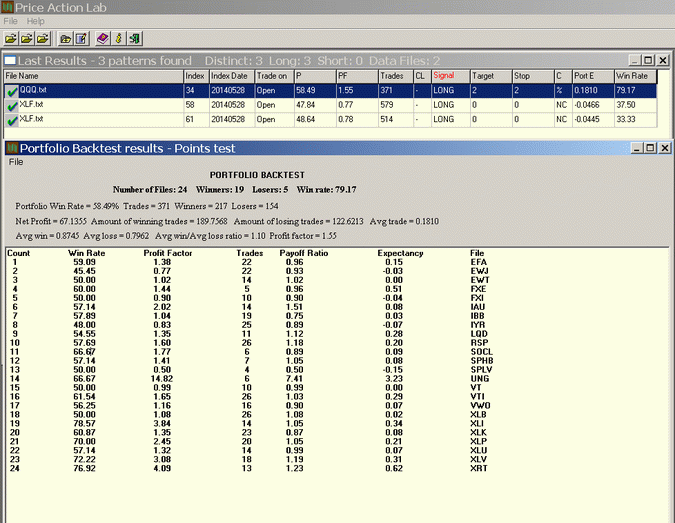 The detailed portfolio backtest report for the pattern in QQQ is also shown. This pattern was profitable in 79.17% (19) of the 24 tickers, the trade sample is 371 and the portfolio profit factor is at 1.55. The portfolio win rate is more than 58%. These results are very promising and show that this pattern in QQQ may not be random. The XLF patterns show negative performance and it is becoming more certain they are flukes. However, a further increase in sample size is desirable to verify the QQQ pattern.
The detailed portfolio backtest report for the pattern in QQQ is also shown. This pattern was profitable in 79.17% (19) of the 24 tickers, the trade sample is 371 and the portfolio profit factor is at 1.55. The portfolio win rate is more than 58%. These results are very promising and show that this pattern in QQQ may not be random. The XLF patterns show negative performance and it is becoming more certain they are flukes. However, a further increase in sample size is desirable to verify the QQQ pattern.
Portfolio backtest on all S&P 500 stocks
The final portfolio backtest is performed using data since inception of all S&P 500 stocks. Below are the results:
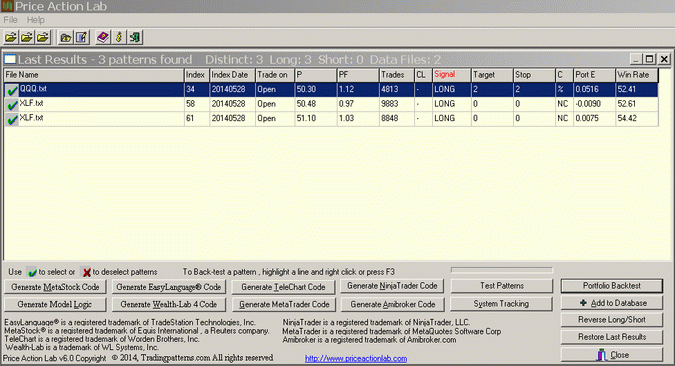
The first observation is that the XLF patterns can be declared random, or artifacts of data-mining bias, or flukes, with high probability. The pattern in QQQ remains profitable with a portfolio profit factor of 1.12 on a sample of 4813 trades. This is a good sample and random patterns usually go flat with that many trades. More than 52% of the S&P 500 stocks are profitable indicate that this pattern has a long bias.
Robustness test
The robustness tests variations in exits and it is done after the portfolio backtests. This is because this type of test always produces good results when the pattern is curve-fitted. Note that some technical analysts attempt to use similar tests to refute curve-fitting.
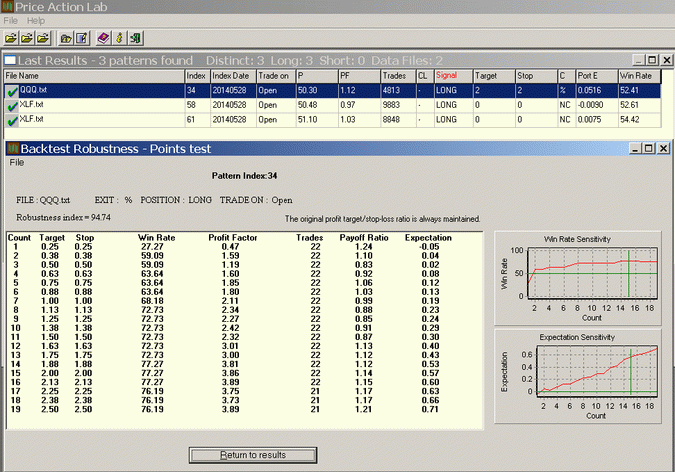
In this test, the profit target and stop-loss are varied so that the ratio is always 1, as originally defined. The trade expectation curve is very smooth and rising and the Robustness Index is at 94.74 (max = 100). Even for small exits in the order of 0.30%, this pattern is profitable with PF = 1.59.
Conclusion
This type of analysis should continue until one is comfortable with the results. Although the probability that a pattern is random may be minimized with the use of portfolio backtests, the next trade may still be a loser, just like when tossing a coin with a winning bias towards heads. This is one reason that the success rate of setups in technical trading must be as high as possible for the purpose of increasing the probability of win of the next trade. Otherwise, non-ergodicity of distributions can result in large drawdown in the short-term.
Technical traders should realize that when they are presented with complicated, ad-hoc, methods for test for data-mining bias, these are in most cases cheap shots at the problem that amount to naive, clueless analysis. The only way to tackle data-mining bias is by increasing the sample size using data actual from comparable securities not used in the data-mining. Some use instead random or synthetic data but these do not represent actual market behavior. One famous fund manager that has promoted the use of random data for determining data-mining bias has been struggling for the last 5 years to generate alpha. I believe the reason these tests are bad is that they more than often result in false acceptance of bad systems and a false rejection of good systems (TYPE I and TYPE II errors).
You can subscribe here to notifications of new posts by email.



