

A high win rate trading system for SPY was machined and designed using a deterministic method and a simple predictor of price. Validation of in-sample results was performed on out-of-samples of SPY and on an anti-correlated security.
The results show that high win rate trading systems with appropriate risk/reward ratio can be machined-designed that are even profitable in an anti-correlated market.
Definitions
Deterministic machine design of trading systems is a process that produces the same result each time it mines the same data with the same design parameters. This is a process compatible with the requirements of scientific testing and analysis. Note that most machine design algos based on neural networks or genetic algorithms do not in general produce the same result when fed with the same data and same parameters due to randomness in initial conditions.
Validation is the process of assessing how the results of machine design perform on an independent data set for the purpose of guarding against Type III errors, i.e., the testing of hypotheses suggested by the data. However, in the case of machine design it is known that simple validation is not sufficient due to multiple hypotheses testing and data-snooping. More advanced procedures of validation are required to assess the significance of trading systems developed via machine design. In this blog, in addition to the out-of-sample test, another strict test is performed on an anti-correlated security during the same unseen data period.
Machine design process
Data set and in-sample performance parameters
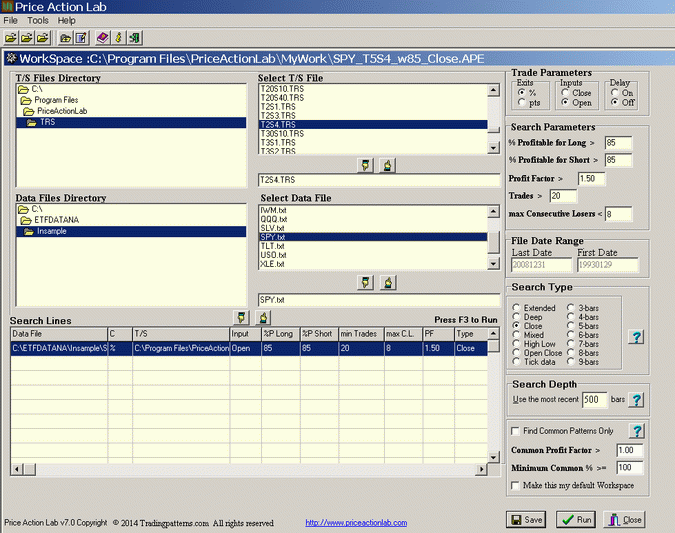
We will use Price Action Lab to machine design a trading system for SPY that will be comprised of a number of short-term price patterns. The close of daily bars will be used as the predictor of price with a maximum look-back period of 9 bars. The available data sample from inception of this ETF is split as follows:
- In-sample: 01/29/1993 – 12/31/2008
- Out-of-sample 01/02/2009 – 04/02/2015
The minimum required win rate for each of the patterns is 85%. The profit target is set to 2% because we would like to avoid as much as possible fitting exits to the data. The stop-loss is set to 4% based on the requirement for a minimum profit factor of 1.5 per pattern identified in the in-sample. We also require that each pattern in the in-sample has more than 20 trades and no more than 7 consecutive losers. Below is the workspace for the in-sample machine design:
Results
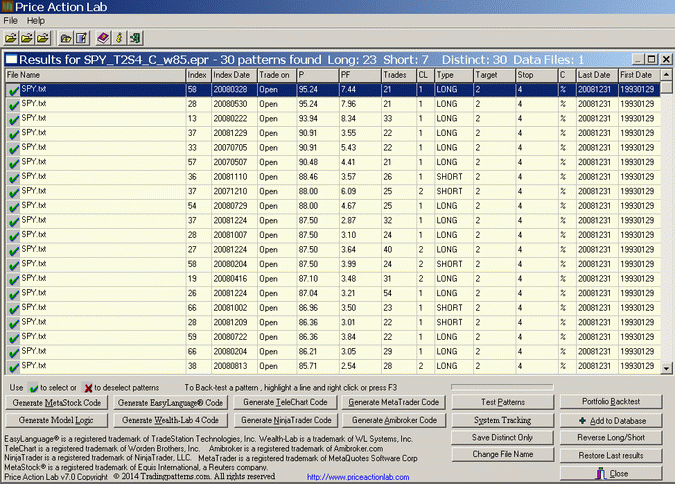
Each line on the results corresponds to a price pattern that satisfies the performance parameters specified by the user. Trade on is the entry point, in this case the Open of next bar. P is the success rate of the pattern, PF is the profit factor, Trades is the number of historical trades, CL is the maximum number of consecutive losers, Type is LONG for long patterns and SHORT for short patterns, Target is the profit target, Stop is the stop-loss and C indicates % or points for the exits, in this case it is %. Last Date and First Date are the last and first date in the historical data file.
Price Action Lab identified 30 distinct patterns that satisfied the criteria specified on the workspace, 23 long and 7 short. Since good performance is guaranteed in the in-sample by design, we will continue with out-of-sample testing. We will just mention that in the in-sample the compound annual return was 22% and Sharpe ratio was 2.57.
Next, Amibroker code was generated for the price patterns and they were combined with the OR operator into a final trading systems.
Validation
The backtest results in the out-of-sample are shown below:
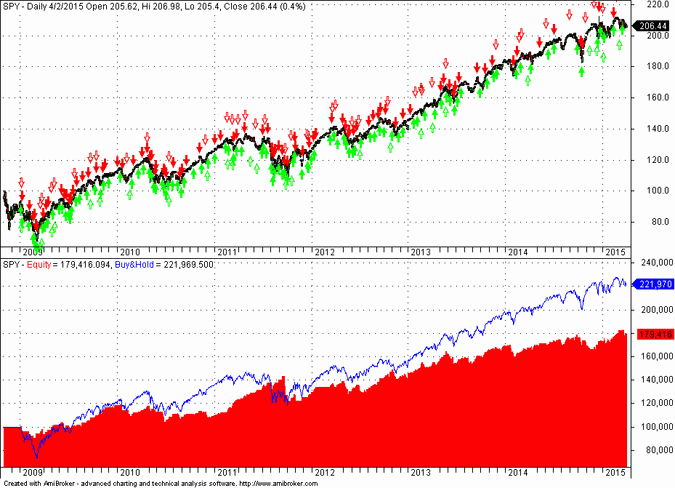
The equity curve is acceptable although below buy and hold (non-adjusted data). However, we should not expect a single system to outperform buy and hold, especially when there is a strong trend during the last two years. The compound annual return is 9.84%, the net return is 79.76%, max. drawdown is -14.92%, profit factor is 1.47 and Sharpe ratio is 1. A total of 150 trades were generated in the out-of-sample, 109 long and 41 short. Short trades contributed about 4.8% to the compound annual return. Note that commission of $0.01 per share was included in the testing and the initial capital was $100K. Equity was fully invested at each new position.
The acceptable results in the out-of-sample does not suffice for the purpose of guarding against Type-III errors. This is true because the machine design process tested many systems in the in-sample before offering a final result. Additional tests are required. Since k-fold cross-validation and other data partitioning methods are difficult to apply in the case of trading systems, we will resort to randomization tests and tests on comparable but anti-correlated securities.
Randomization test
Below is the distribution of net returns of 20,000 random long/short SPY trading systems that initiate positions at the close of daily bar in the out-of-sample based on the outcome of a fair coin toss (heads = long, tails = short). Long positions are closed when tails come up and short positions are closed when heads show up. Starting equity is $100K, commission is set at $0.01 per share and equity is fully invested at each position:
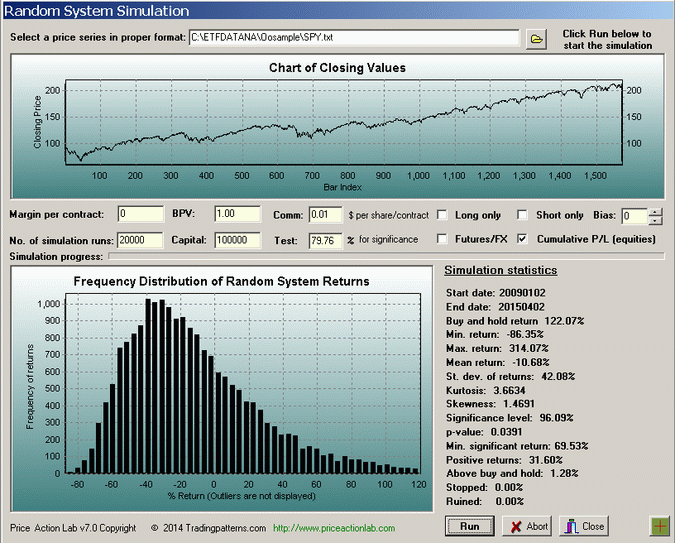
The net return of 79.76% in the out-of-sample of the machine designed system for SPY scores higher than 96.09% of the random systems, resulting in a p-value of 0.0391. Therefore, given that the null hypothesis is true, the probability of obtaining the tested return in the out-of-sample by chance is about 4%. But is it really? The answer is that maybe it is not and it is actually higher. We need additional validation.
A strict cross-validation test
Since our system was developed by essentially performing multiple tests, the above randomization analysis is a first step in ruling out Type-III errors but it does not suffice. We can use such this analysis to save time in the sense that if the p-value is higher than 0.05 we can then reject the system. But a high p-value does not rule out a spurious system due to multiple testing, i.e., a system that was lucky enough to pass the randomization test.
For the purpose of increasing the chances that our result is not spurious, we will identify an anti-correlated security in the out-of-sample period and test the system. A good candidate for this test is TLT, as shown below:
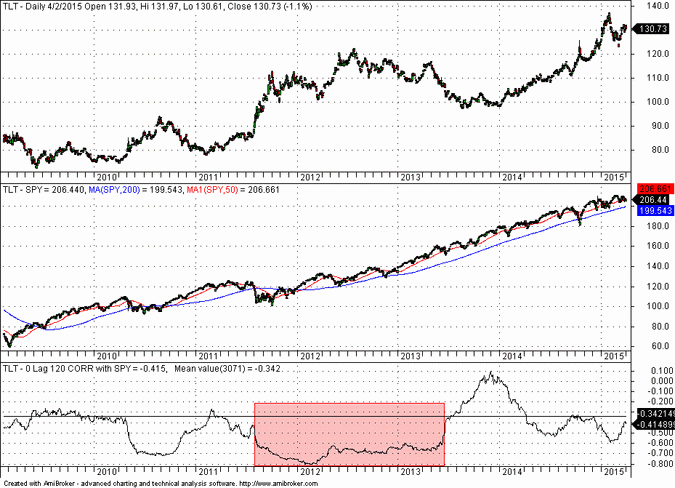
The average 120-day correlation of SPY and TLT during the out-of-sample period was -0.34 with a period of nearly two years, which is marked on the chart, of high anti-correlation. Below is the equity performance of the system developed for SPY on TLT data in the same out-of-sample period:
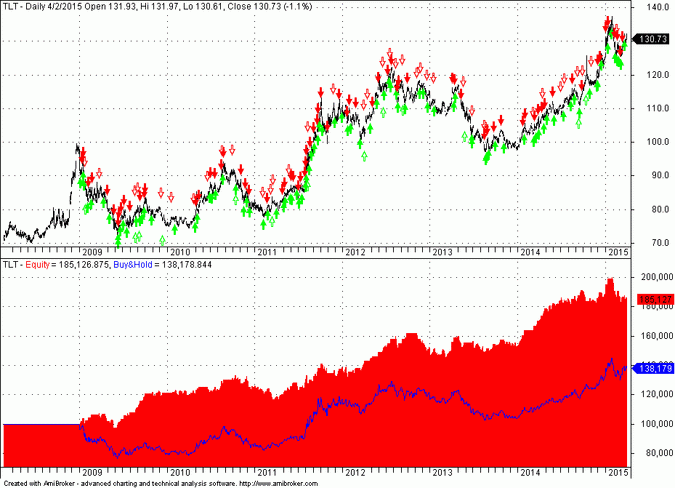
In the case of TLT the system outperforms buy and hold with compound annual return of 9.43% and net return of 75.60%. Max. drawdown is -11.14% and Sharpe is 1.06 with profit factor equal to 1.49.
This is a significant result. A system developed for SPY works even better on TLT, an anti-correlated security. Thus, the probability that the patterns identified during machine design have predictive power is high. However, note that this test must be performed only once. If the results are not satisfactory, searching for another anti-correlated security that will provide a positive result, or for another system that will provide a positive result with the same test, introduces data-snooping bias and invalidates the significance of these tests. The same applies to any process that reuses data to perform tests in an out-of-sample. If the data is reused many times, data-fishing is guaranteed along with spurious results. Apparently, this is what plagues the efforts of many system developers that use neural networks and genetic algorithms to mine for edges. This is also why determinism is important: If a different system is mined at every new trial, or there are many different systems with good performance, this facilitates data-snooping. However, with Price Action Lab this is not possible because with the same parameters, the same system will be found and all patterns are used to develop the final system, i.e., there is no selection bias.
Randomization test
Below is the distribution of net returns of 20,000 random long/short TLT trading systems that initiate positions at the close of each daily bar in the out-of-sample based on the outcome of a fair coin toss (heads = long, tails = short). Starting equity is $100K, commission is set at $0.01 per share and equity is fully invested at each position:

The net return of 75.60% of the machine designed system for TLT scores higher than 97.47% of the random systems, resulting in a p-value of 0.0253. Therefore, given that the null hypothesis is true, the probability of obtaining the system results in the out-of-sample by chance is about 2.5%.
Conclusion
Simple predictors of price action, such as the close of daily bars, still possess predictive power despite a continuous arbitrage of opportunities in the markets. This was demonstrated in this blog. It is important that the machine design that uses a simple predictor to develop an algo is deterministic; otherwise complex tests must be used to guard against Type-III errors and data-fishing. The complexity of the required tests render the application of machine design based on random initial conditions extremely difficult in the case of trading system development. Due to the deterministic nature of the machine design algorithm used in this example, a simpler but strict test was used based on the performance of the system on an anti-correlated security. However, any abuse of these types of tests renders them ineffective in guarding against Type-III errors. Obviously, trading system development is not easy and it is getting harder as technology progresses. Traders have two options when developing systems: The first option is based on conceiving a hypothesis to test that must be unique, otherwise it may be an artifact of data-mining bias. The second option involves using machine design. Both options have pitfalls. The first option requires uniqueness and the second option requires effective cross-validation tests. It may be the case that coming up with a unique hypothesis has low chances due to relentless data-mining in the last 25 years using computers and backtesting.
You can subscribe here to notifications of new posts by email.
Charting program: Amibroker
Disclaimer
© 2015 Michael Harris. All Rights Reserved. We grant a revocable permission to create a hyperlink to this blog subject to certain terms and conditions. Any unauthorized copy, reproduction, distribution, publication, display, modification, or transmission of any part of this blog is strictly prohibited without prior written permission.



